Wir betreiben derzeit (Stand Juli 2022) 1300 Linux-Maschinen. Alle diese Maschinen brauchen regelmäßige Wartungen, z.B. für Sicherheitsupdates. Wie können wir diese Wartungen durchführen, ohne dass wir zu nichts anderem mehr kommen?
Ein einfacher Ansatz wäre, in einer Software wie Rundeck oder Ansible der Reihe nach alle Maschinen durchzugehen und die Wartung durchzuführen. Dieser Ansatz kann funktionieren, wenn die Maschinen austauschbar sind, d.h. wenn sie identisch konfiguriert sind.
Wir betreiben aber verschiedenste Anwendungen für verschiedenste Kunden. Wenn wir mehrere Maschinen willkürlich herunterfahren würden, dann hätten wir das Risiko, dass wir alle Maschinen einer bestimmten Anwendung genommen haben und eine Downtime verursachen. Daher muss unser Ansatz durchdachter sein.
Das Konzept
Als erstes gruppieren wir alle Maschinen in Sets, basierend auf ihrem Projekt, ihrer Funktion und ihrem Clusterverbund. Innerhalb eines solchen Sets sind die Maschinen austauschbar – z.B. alle Worker-Nodes eines einzelnen Kubernetes-Cluster oder alle Nodes eines Patroni-Clusters. Aus jedem Set warten wir nur 10% der Maschinen gleichzeitig, so dass genug Kapazität verfügbar bleibt.
Mit diesen Sets könnten wir theoretisch die Maschinen durchgehend warten, unabhängig davon ob eine Wartung notwendig ist. Allerdings gibt es zeitaufwändige Wartungen, z.B. wenn ein KVM-Host erst alle laufenden VMs weg migrieren muss, bevor er rebootet werden kann. Daher wollen wir nur Wartungen durchführen, wenn sie notwendig sind, z.B. wenn Updates von Softwarepaketen ausstehend sind.
Leider können nicht alle Anwendungen zu jedem Zeitpunkt gewartet werden, z.B. weil sie nicht hochverfügbar sind oder weil eine Wartung bestimmte langlaufende Anfragen unterbrechen würde. Wir müssen also bestimmte Blocker berücksichtigen.
Zusätzlich müssen wir sicherstellen, dass eine Wartung einer Maschine problemlos war, bevor wir mit den anderen Maschinen im gleichen Set fortfahren. Wenn wir ein problematisches Update ausrollen und die Anwendung auf der Maschine nicht mehr erreichbar ist, sollte das Update nicht auf die weiteren Maschinen ausgerollt werden.
Die Implementierung
Unsere Anwendung Automainter ist die Implementierung dieses Konzepts. Er erfasst zu jeder Maschine drei Arten von Indikatoren:
- MaintenanceRequired: Auslöser für eine Wartung
- Blocked: Blocker, die eine Wartung dieser Maschine verhindern
- Unavailable: Probleme mit dieser Maschine, welche die Wartungen der anderen Maschinen im Set blockieren, bis sie behoben sind
Einige Beispiele für Indikatoren bei uns sind:
- MaintenanceRequired
- ein Paketupdate muss eingespielt werden
- ein neues Kernel-Image muss durch einen Reboot aktiviert werden
- Blocked
- die automatische Wartung ist aktuell für diesen Maschinen-Typ deaktiviert, weil es dabei Probleme mit einer Software gab
- auf der Maschine läuft ein Kubernetes-Pod, der wegen eines Pod Disruption Budgets derzeit nicht evictet werden kann
- es ist gerade jemand per SSH angemeldet
- Unavailable
- Prometheus kann die Maschine nicht erreichen
- unser HAProxy-Loadbalancer meldet einen fehlerhaften Health-Check für diese Maschine
- das Kubelet auf dieser Kubernetes-Node meldet sich nicht als Ready
Das sieht dann z.B. so aus:

Die Quelle für diese Indikatoren sind Prometheus-Alerts, die jeweils eine entsprechende Markierung (Alert-Annotation) gesetzt haben, die bestimmt, welche Art von Indikator sie sind.
Der Automainter läuft durchgehend und prüft minütlich den Status aller Sets und ihrer Maschinen. Er startet eine Wartung für eine Maschine, wenn:
- die Maschine eine Wartung benötigt und
- die Maschine keine Blocker hat und
- maximal 10% der Maschinen des Sets down wären, während die Wartung läuft.
Zur Durchführung der Wartung startet der Automainter einen Job im Rundeck, welcher alles weitere erledigt:
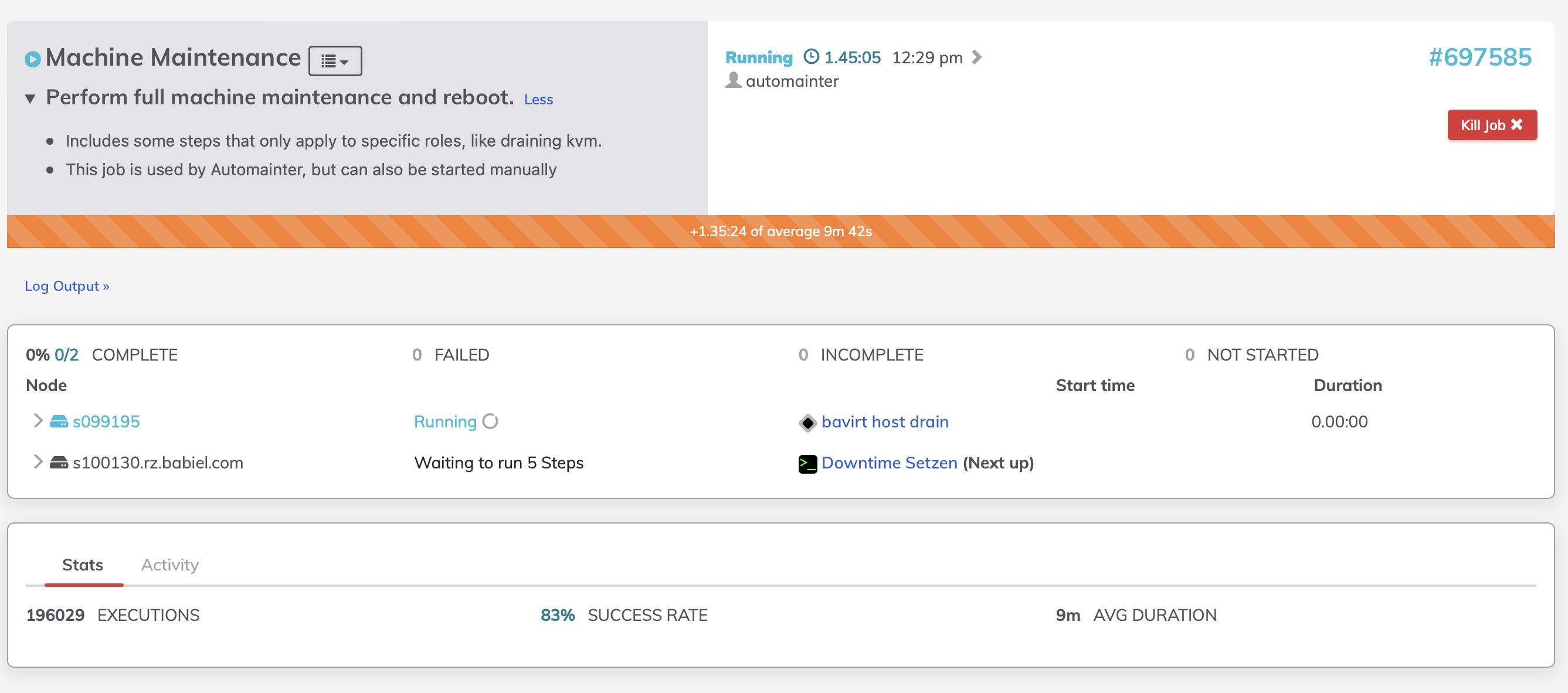
Rundeck ist ein Tool um Jobs mit definierten Schritten zu erstellen, die dann mit bestimmten Maschinen ausgeführt werden können. Unser Rundeck-Job für die Wartung bereitet die Maschine für Wartung vor (z.B. mit kubectl drain), spielt alle offenen Paketupdates ein und macht dann einen Reboot der Maschine. Nach Bedarf kann der Job um weitere spezialisierte Schritte erweitert werden, z.B. um die Container-Runtime auf Kubernetes-Nodes von Docker auf containerd umzustellen.
Der Status der Rundeck-Ausführungen wird ebenfalls als Indikator verwendet: während ein Rundeck-Job läuft und für einige Zeit danach gilt die Maschine als Unavailable, was wiederum die Wartung weiterer Maschinen in diesem Set verhindert. Dadurch verzögern wir innerhalb eines Sets den Rollout: falls es Probleme mit Änderungen gibt, können wir diese bemerken, bevor alle Maschinen eines Sets betroffen sind.
Fazit
Durch den Automainter passieren die allermeisten Wartungen bei uns vollautomatisch. Wir werden lediglich über ausstehende Wartungen informiert, wenn diese längere Zeit im Automainter blockiert sind. Dann müssen wir eingreifen und die Indikatoren optimieren, damit die Wartung in Zukunft automatisch passieren kann oder notfalls die Wartung manuell durchführen.

Die Maschinen kümmern sich um sich selbst und eskalieren nur an uns, wenn das nicht funktioniert. Der integrierte inkrementelle Rollout von Änderungen bedeutet, dass mehr Änderungen inkrementell passieren, weil man diesen Rollout nicht mehr selbst koordinieren muss.
Kurz gesagt: Der Automainter bedeutet für uns eine dramatische Reduktion von Toil – wir haben mehr Zeit für spannendere Tätigkeiten. Falls du auch Interesse hast an und mit solchem Tooling zu arbeiten, bewirb dich doch bei uns 🙂