Was ist das, wozu brauchen wir das und was ist daran so kompliziert?
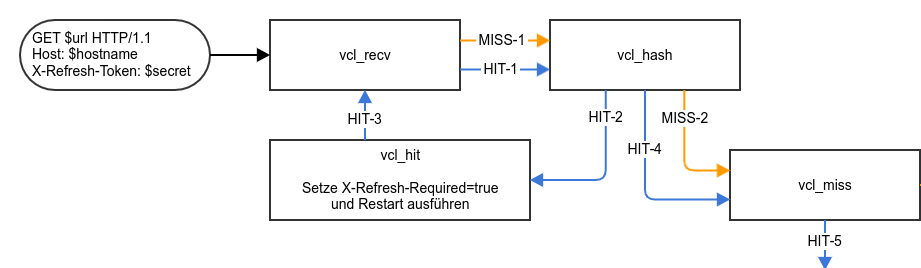
Ein Health-Check-Cache soll, wie der Name schon vermuten lässt, Health-Checks cachen. In Wirklichkeit passiert aber noch mehr, was für uns auch sehr wichtig ist.
Unsere Loadbalancer laufen mit HAProxy. Dieser macht regelmäßig Health-Checks gegen die Backends. Das ist auch gut und richtig, denn er muss ja immer wissen, welches Backend tatsächlich up oder down ist, um den Traffic für den User möglichst ohne Unterbrechung oder Fehler zu lenken. Wenn man jetzt, so wie wir, sehr viele Loadbalancer hat und diese auch noch innerhalb sehr kurzer Zeit vervielfachen kann, wird das jedoch ab einem gewissen Punkt zu einem Problem und skaliert einfach nicht mehr, was die Health-Checks angeht.
Stellen wir uns 50 Loadbalancer vor, die alle N Sekunden gegen ein und das selbe Backend prüfen. Dazu kommt der normale Traffic, der nicht aus dem Cache ausgeliefert wird, oder der gerade im Cache expired ist, plus vielleicht noch eine „nicht optimale“ Backendsoftware, die einfach nicht so viele Requests pro Sekunde schafft. Das alles in Kombination ist denkbar ungünstig. Das Ziel eines Caches ist es ja, das Backend zu entlasten und die Auslieferung bestenfalls noch zu beschleunigen. Selbiges können wir auch für Health-Checks tun. Wieso sollen alle 50 Loadbalancer einzeln ihre Health-Checks gegen die Backends fahren? Auch hier kann man das super konsolidieren, indem wir nur für die Health-Checks einen Cache betreiben und der HAProxy gegen den Cache prüft.
Das Backend bzw. die Software können wir uns leider nicht in jedem Fall aussuchen oder so beeinflussen, dass sie für uns ausreichend performt. Also brauchen wir eine Lösung, die wir einfach überall anwenden können, unabhängig vom eigentlichen Backend. Da passt ein solcher Cache sehr gut ins Konzept.
„Health-Check-Cache für HTTP-Backends“ weiterlesen