Wir verwalten alle unsere über 1000 Linux-Maschinen zentral mit Puppet. Puppet Server ist also eine wichtige Komponente unserer Infrastruktur. Wenn Puppet nicht zuverlässig läuft, können wir nicht ordentlich arbeiten.
In solche wichtigen Komponenten wollen wir Einblick, damit wir bei Problemen verstehen können wo es klemmt. Deswegen sammeln wir generell alle möglichen Daten mit Prometheus ein und werten diese in Grafana-Dashboards aus.
Das Problem
Leider bekommen wir aus Puppet Server keine brauchbaren Metriken.
Das erste Problem ist, dass Puppet Server gar keine Metriken für Prometheus bereitstellt. Es gäbe zwar zahlreiche Werte per JMX, die wir mit dem jmx_exporter für Prometheus verfügbar machen könnten. Leider sind die Metriken aber nicht so aufgebaut, wie es für uns nützlich wäre:
- Für Prometheus sollte ein Programm möglichst „rohe“ Daten exportieren. Die Werte sind aber bereits voraggregiert, z.B. in einen Durchschnitt, bei dem wir nicht wissen, über welchen Zeitraum der gebildet wird.
- Die Werte sind nicht aufgeschlüsselt nach verschiedenen API-Endpoints, d.h. wir können nicht sehen welche Requests langsam beantwortet werden.
Accesslog als Datenquelle
Es gibt aber einen Ort, wo Puppet Server für uns interessante Werte ablegt: in seinem HTTP-Accesslog. Das Log hat dieses Format:
192.168.150.130 - - [26/Jan/2022:13:50:55 +0100] "POST /puppet/v3/catalog/s150130.rz.babiel.com?environment=production HTTP/1.1" 200 899277 "-" "Puppet/7.14.0 Ruby/2.7.5-p203 (x86_64-linux)" 3700 21726 3692Das Format entspricht großteils dem von Apache, mit einigen Puppet-spezifischen Erweiterungen. Die für uns interessanten Felder sind:
- der API-Endpoint: /puppet/v3/catalog
- der HTTP-Statuscode: 200
- die Responsezeit: 3700 ms
- die JRuby-Borrow-Dauer: 3692 ms
Die JRuby-Borrow-Dauer ist eine Spezialität von Puppet Server. Puppet Server ist in Clojure programmiert und läuft in der JVM (Java Virtual Machine). Der Großteil des Code von Puppet, insbesondere der Compiler, ist aber weiterhin in Ruby implementiert und wird vom Puppet Server in JRuby ausgeführt. Puppet Server hat dazu einen Pool von JRuby-Instanzen. Die JRuby-Borrow-Dauer gibt an, wie lange eine JRuby-Instanz aus diesem Pool für die Bearbeitung des Requests belegt wurde. Diese JRuby-Instanzen sind für die allermeisten Requests das Bottleneck.
mtail
Mit mtail bekommen wir die Daten aus dem Accesslog in unseren Prometheus. mtail läuft auf der gleichen Maschine wie Puppet Server, liest fortlaufend das Log und erzeugt daraus Metriken. Die Metriken können wir dann einfach per HTTP scrapen.
mtail führt dazu Code in seiner eigenen DSL (Domain Specific Language) aus. Zuerst müssen wir unsere Metriken definieren:
# Das Histogram hat viele Buckets im Bereich von 1-10s, weil dort die meisten Puppet-Compiles liegen.
# Mit weniger Buckets könnten wir keinen Unterschied zwischen z.B. 8s und 6s sehen.
histogram puppetserver_http_request_duration_seconds by endpoint, status_code buckets 0.01, 0.05, 0.1, 0.5, 1, 2.5, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 60, 120, 240
histogram puppetserver_jruby_borrow_seconds by endpoint buckets 0.01, 0.05, 0.1, 0.5, 1, 2.5, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 60, 120, 240Wir erstellen zwei Histogramm-Metriken:
- puppetserver_http_request_duration_seconds, aufgeteilt mit den Labels endpoint und status_code
- puppetserver_jruby_borrow_seconds, aufgeteilt nach dem Label endpoint
Dann können wir mit einem Regex Logzeilen matchen:
/^/ +
/(?P<remote_host>[0-9A-Za-z\.:-]+) / + # %h
/(?P<remote_logname>[0-9A-Za-z-]+) / + # %l
/(?P<remote_username>[0-9A-Za-z-]+) / + # %u
/\[(?P<timestamp>\d{2}\/\w{3}\/\d{4}:\d{2}:\d{2}:\d{2} (\+|-)\d{4})\] / + # %u
/"(?P<request_method>[A-Z]+) (?P<endpoint>\/[^\/]+\/[^\/]+\/[^\/]+)[\/?]\S+ (?P<http_version>HTTP\/[0-9\.]+)" / + # \"%r\"
/(?P<status_code_digit>\d)\d{2} / + # %>s
/((?P<response_size>\d+)|-) / + # %b
/"(?P<referer>\S+)" / + # \"%i{Referer}\"
/"(?P<user_agent>[[:print:]]+)" / + # \"%i{User-agent}\"
/(?P<response_time>\d+) / + # %D
/((?P<request_size>\d+)|-) / + # %i{Content-Length}
/((?P<jruby_borrow_time>\d+)|-)/ + # %mdc{jruby.borrow-time:--}
/$/ {
puppetserver_http_request_duration_seconds[$endpoint][$status_code_digit + "xx"] = $response_time / 1000.0
$jruby_borrow_time != "-" {
puppetserver_jruby_borrow_seconds[$endpoint] = int($jruby_borrow_time) / 1000.0
}
}
Zu jedem Regex gehört ein Block, der ausgeführt wird, wenn die Zeile auf den Regex passt. Die im Regex definierten Gruppen sind als Variablen in diesem Block verfügbar. Diese Variablen nutzen wir dann um unsere Metriken zu setzen.
Wir legen unser Programm in /etc/mtail/puppetserver.mtail ab und führen mtail dann so aus:
mtail -progs /etc/mtail -emit_prog_label=false -alsologtostderr -logs /var/log/puppetlabs/puppetserver/puppetserver-access.logPer HTTP auf Port 3903 unter /metrics bekommen wir dann u.a. diese Metriken:
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="0.01"} 0
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="0.05"} 0
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="0.1"} 0
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="0.5"} 6
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="1"} 8
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="2.5"} 8473
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="3"} 18616
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="4"} 29412
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="5"} 33637
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="6"} 35407
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="7"} 36378
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="8"} 36943
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="9"} 37318
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="10"} 37566
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="15"} 38369
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="20"} 39034
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="30"} 39645
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="60"} 40258
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="120"} 40473
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="240"} 40483
puppetserver_http_request_duration_seconds_bucket{endpoint="/puppet/v3/catalog",status_code="2xx",le="+Inf"} 40483
puppetserver_http_request_duration_seconds_sum{endpoint="/puppet/v3/catalog",status_code="2xx"} 207944.94300000006
puppetserver_http_request_duration_seconds_count{endpoint="/puppet/v3/catalog",status_code="2xx"} 40483
Ergebnisse
Aus diesen Metriken können wir die für uns interessanten Abfragen bauen, entsprechend der RED-Methode (Rate, Errors, Duration).
% der Responses mit Fehler, aufgeteilt nach Endpoint
sum(rate(puppetserver_http_request_duration_seconds_count{status_code="5xx"}[$__rate_interval])) by (endpoint) / sum(rate(puppetserver_http_request_duration_seconds_count[$__rate_interval])) by (endpoint)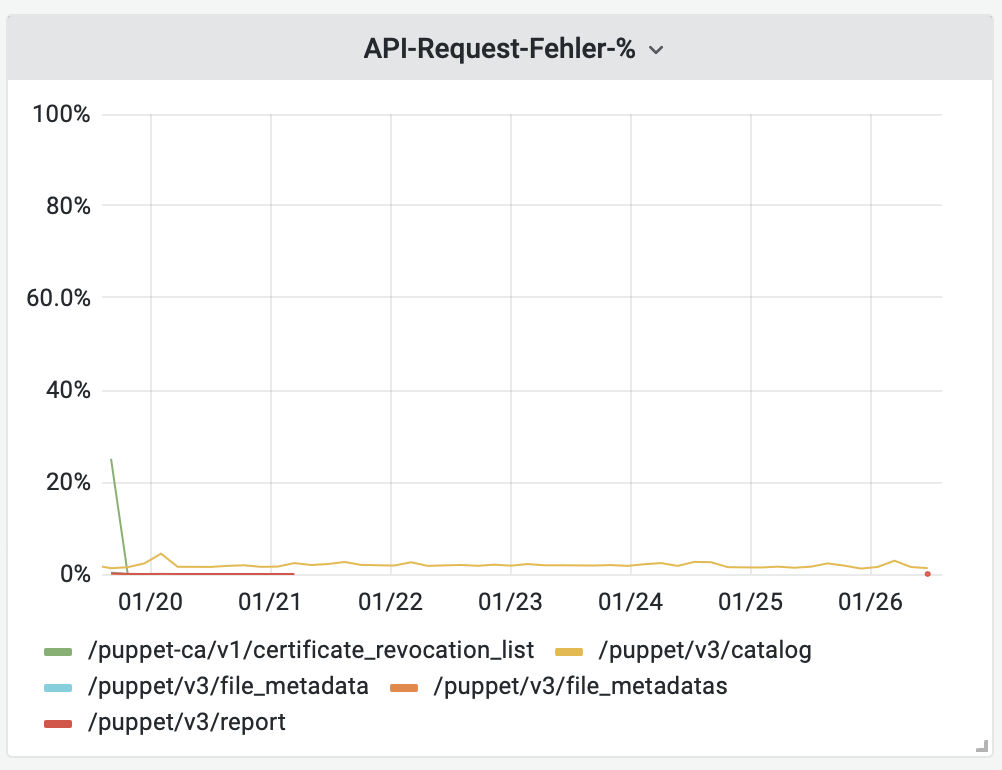
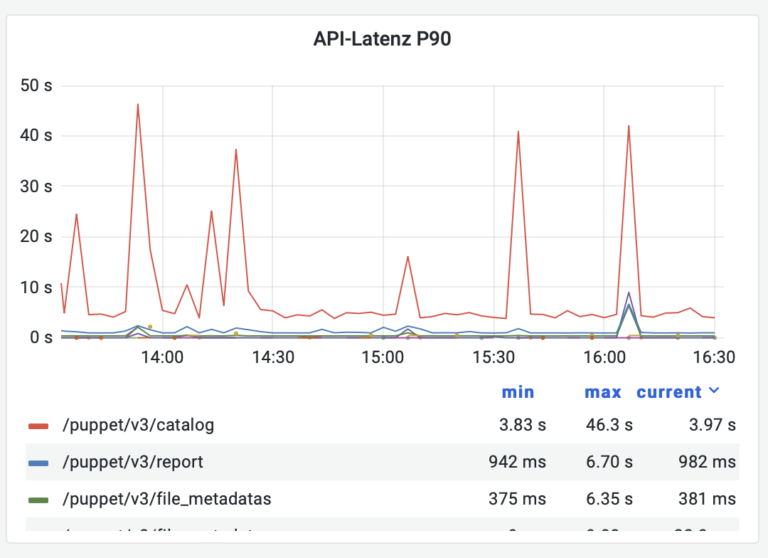
90th Percentile der Responsezeiten, aufgeteilt nach Endpoint
histogram_quantile(0.9, sum(rate(puppetserver_http_request_duration_seconds_bucket[$__rate_interval])) by (le, endpoint))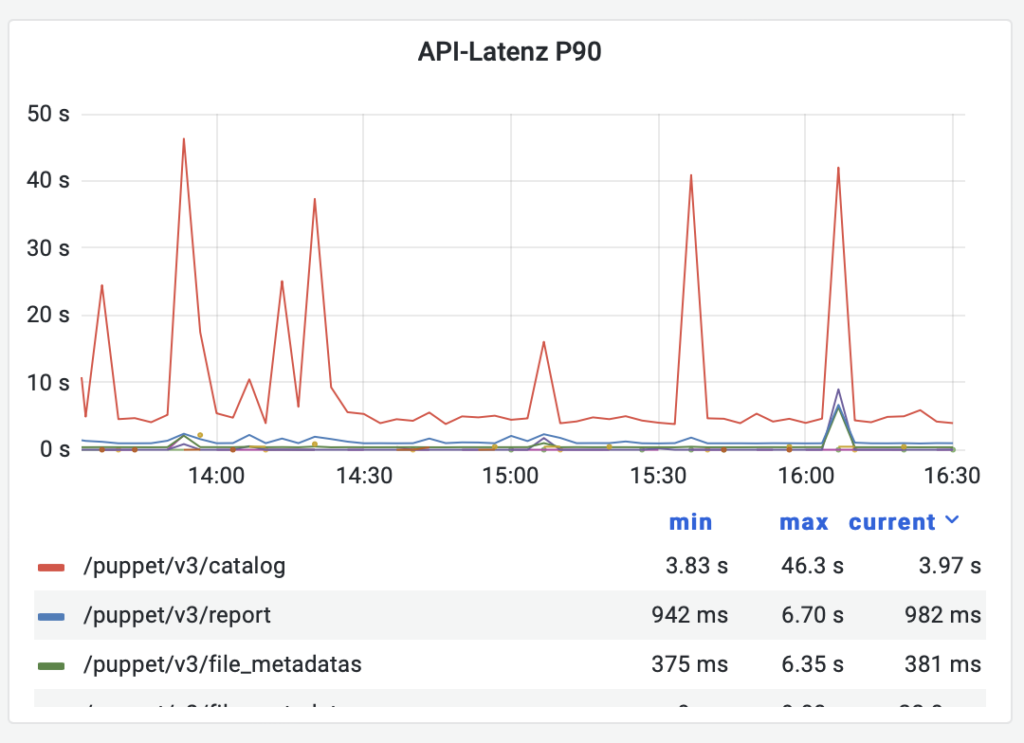
Diese Auswertung ist sehr nützlich bei Performanceproblemen – wir können sehen welche Endpoints länger dauern, woraus wir schließen können, wo es klemmt.
In dem Screenshot sieht man, dass Abfragen des Catalogs für einen kurzen Zeitraum deutlich länger dauern. Das passiert, wenn neuer Code deployt und der Cache geflusht wird.
Request-Rate (Requests pro Sekunde)
sum(rate(puppetserver_http_request_duration_seconds_count[$__rate_interval])) by (endpoint)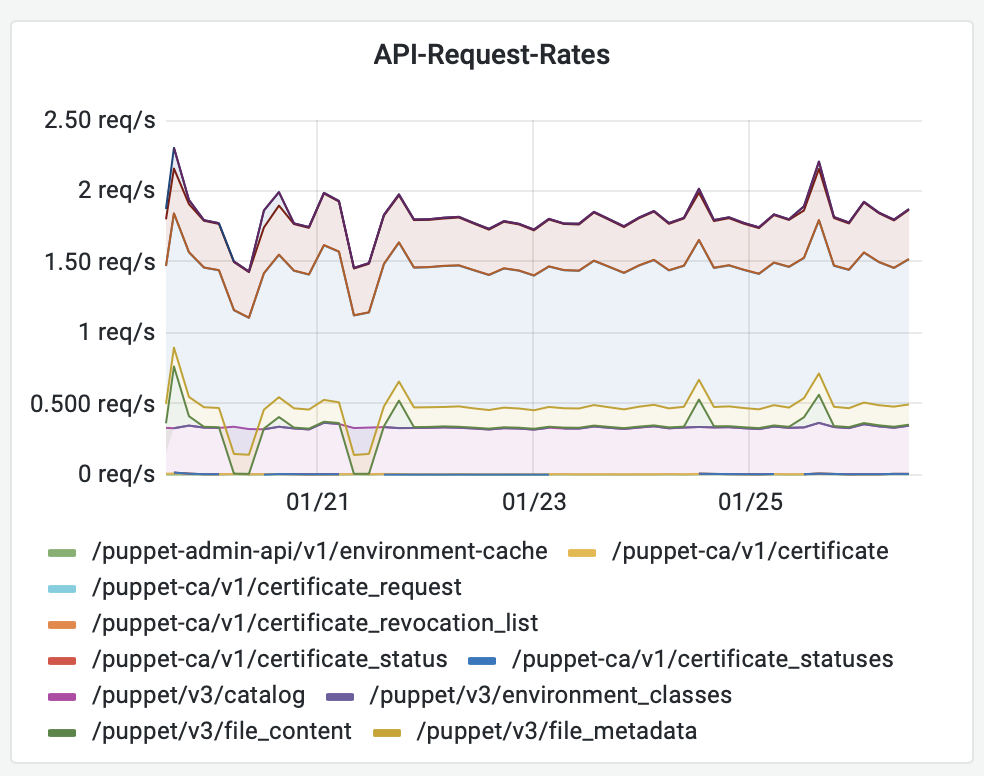
Dieses Panel ist selten interessant, außer wenn es einen auffälligen Anstieg der Menge an Requests gibt.
90th Percentile JRuby-Borrow-Dauer
histogram_quantile(0.9, sum(rate(puppetserver_jruby_borrow_seconds_bucket[$__rate_interval])) by (le, endpoint))ª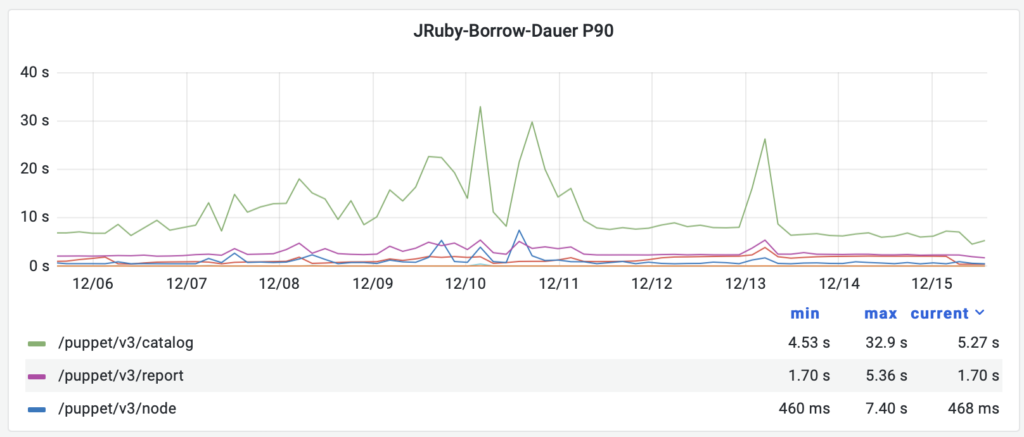
In dieser Auswertung sehen wir wie lange ein Request eine JRuby-Instanz belegt. Das kann sehr nützlich sein wenn man es mit den HTTP-Responsezeiten vergleicht: wenn ein Request lange braucht, aber dann deutlich kürzer ein JRuby belegt, dann hat er höchstwahrscheinlich die meiste Zeit davor in der internen Queue des Puppet Server verbracht und auf ein freies JRuby gewartet.
Einige Endpoints tauchen in diesem Panel nicht auf – diese werden von Puppet Server komplett ohne Ruby-Code beantwortet (z.B. die komplette API für die Puppet-CA).
Fazit
Es ist ideal, wenn ein Programm nützliche Metriken für Prometheus bereitstellt. Wenn es das nicht tut, kann man aber oft nachhelfen, indem man die Logs mit mtail in die gewünschten Metriken verwandelt. Neben dem Puppet Server verwenden wir mtail auch für HAProxy (HTTP-Responsezeiten), Postfix und Hybris. Weitere Beispiele für mtail befinden sich in dessen GitHub-Repo.
Falls dieser Artikel dein Interesse geweckt hat, we are hiring 😉